.svg)

A single pane of glass for self-service computational science
Get computational teams up and running faster in the cloud, less dependent on IT and engineering resources, and using standardized computing environments across your organization.
Key benefits for IT & engineering teams
Import, deploy, & manage custom environments
Admin controls allow for the deployment and management of starter environments for use in computational research. Enforce standards across teams, or an entire organization.

Integrate with your IdP
Code Ocean integrates SAML and OIDC as well as SCIM to allow administrators to control access to the system from a central Identity provider. AWS Assumable Roles integration also allows administrators to assign IAM roles.

Granular analytics for compute and storage costs
Monitor your entire deployment for usage, costs, storage, and activity. View as a whole or get cost per run, dataset, user, or project. Option to limit the availability of dedicated machines, and take control of Capsules if costs run higher than expected.

Self-service provisioning for research teams
Straightforward controls and built-in auto-generated Dockerfiles allow computational teams to quickly build, manage, and re-use their environments, then assign computing resources to their work without support.

FAIR data architecture and improved data efficiency
Code Ocean installs directly in your AWS VPC. S3 data can be attached to multiple concurrent Capsules or Pipelines, by multiple users, without duplication. All recently used internal Data are cached to EFS for fast access.

Connect via the API to automate workflows
Get programmatic access without using the user interface. Tap into core functionality to enable automated running of Computations, creation of Data Assets, metadata retrieval, and more.

What organizations use Code Ocean?
What our customers say:
“No matter where we are in our tech stack, when we onboard a new member of the team, whether it’s a scientist or bioinformatician or software engineer, I set it up so they’re producing value very quickly.”

What our customers say:
“Code Ocean opens the door to automating and scaling major aspects of the research process. With the Code Ocean platform, our scientists can focus on their core competencies, do more, think bigger, and achieve higher goals.”

What our customers say:
“Code Ocean sped up our internal image pre-processing computational workflow by at least 10x, improving collaboration and productivity between our global teams ... removing the need for painful cloud computing infrastructure set up.”

Key product features

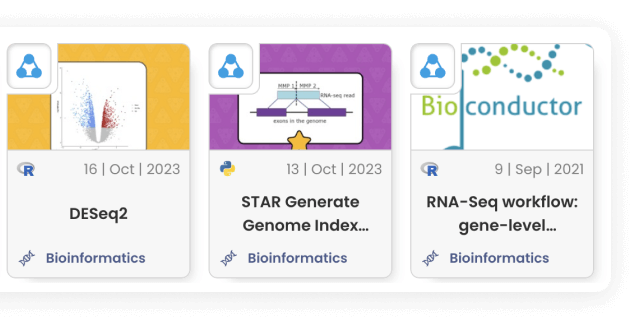
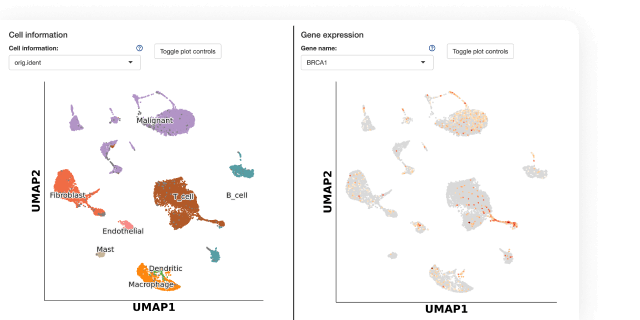
Built for Computational Science
-
Data analysis

Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
-
Data management

Data management
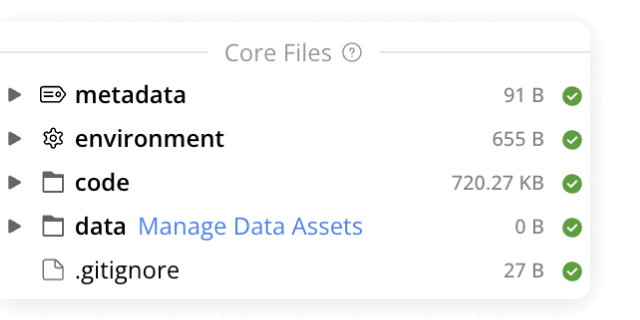
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
-
Bioinformatics pipelines

Bioinformatics pipelines
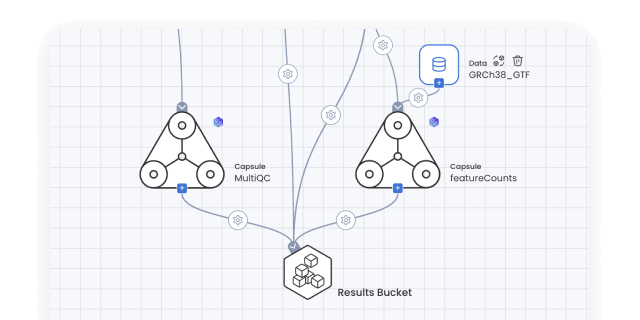
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
-
ML models
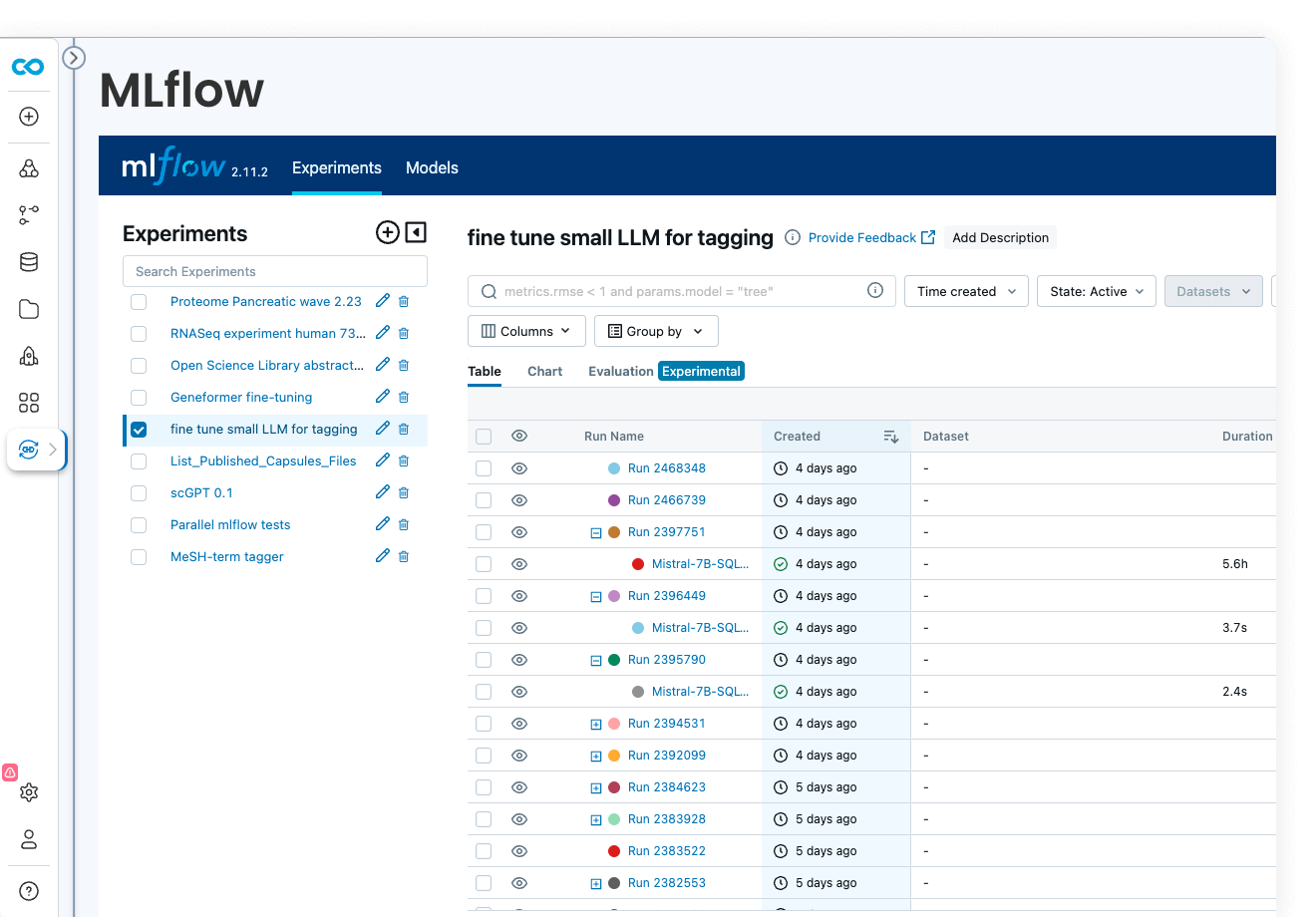

ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
-
Multiomics


Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
-
Imaging
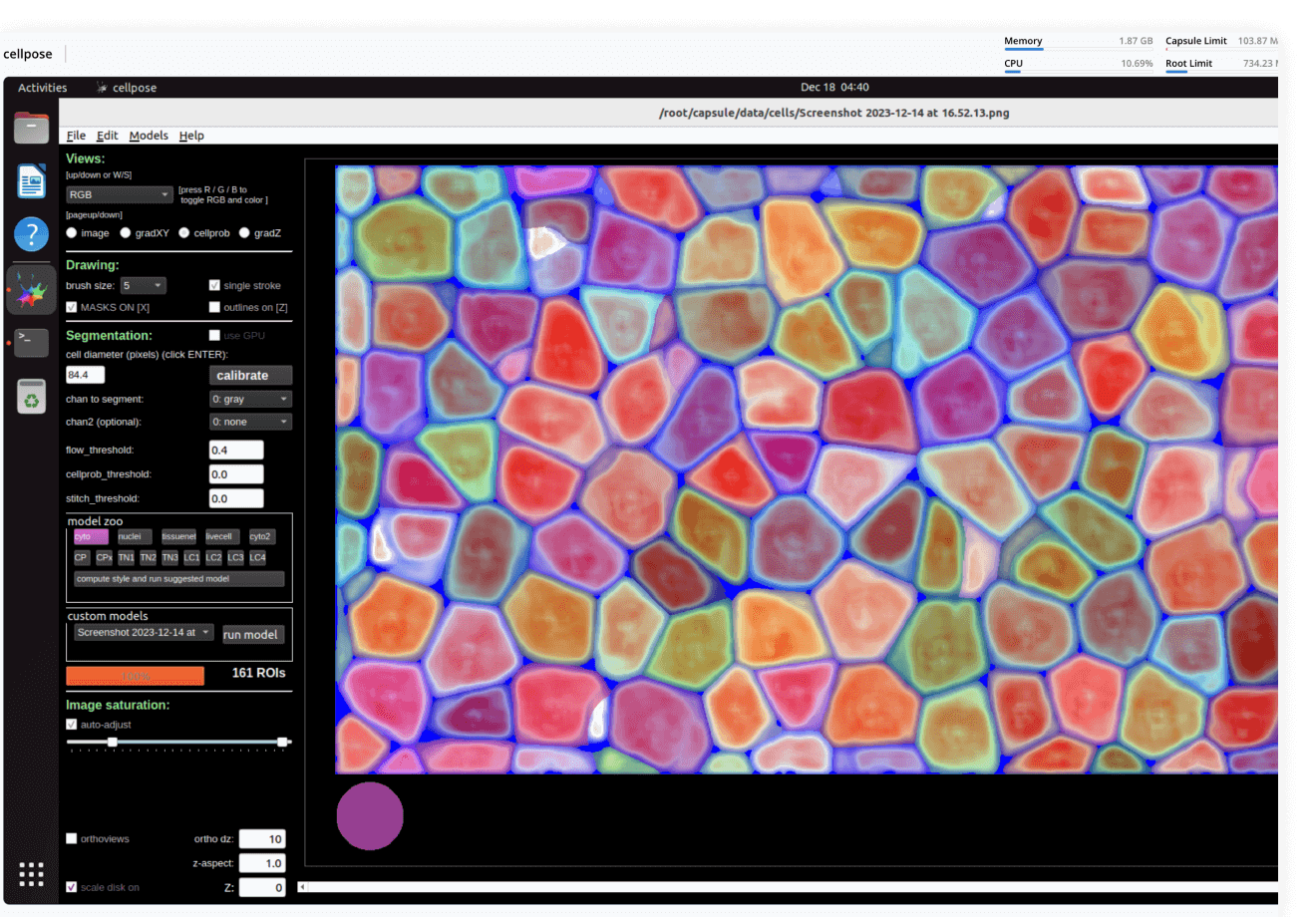

Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
-
Cloud management


Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
-
Data/model provenance

Data/model provenance
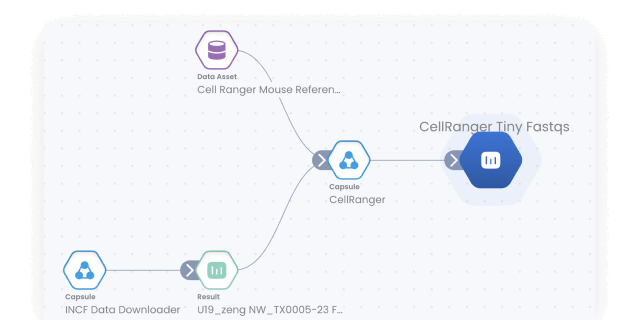
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
.png?length=720&name=September%20Webinar%20-%20On%20Demand%20(1).png)
