.svg)

Compute Capsules
A shareable, traceable, reproducible encapsulation of the code, data, and environments used in computational research, version controlled and linked to the results they produce.


Key capabilities
Set up environments with automated Dockerfile generation
Choose your environment and add packages while the Capsule automatically writes your Dockerfile. Work with the included base images or import your own. Optionally unlock the Dockerfile to customize your script.

Provision and manage compute resources
Select from Flex compute options, or choose a dedicated EC2 instance with optional spot instance selection. Instances automatically terminate when idle for 2 hours. No compute cost pass-through: Code Ocean installs in your AWS cloud environment.

Launch cloud workstations
Choose from a selection of integrated IDEs and virtual machines to begin developing within your Capsule. Includes: JupyterLab, RStudio, Jupyter Notebook, Shiny, MATLAB, VS Code, Streamlit, Ubuntu Desktop, and IGV.

Track everything with automated Git
Everything developed in a Capsule gets automatically tracked with Git without the user having to know Git or set it up—everything is automated. Connects to GitHub, GitLab, Bitbucket, or Azure DevOps.

Share your work with other users or groups
Share Capsules with other users or groups on your team with user permissions built-in. Work on the Capsule collaboratively, or clone and adapt for your own needs. Option to share all assets associated.

How Compute Capsules work with the rest of the Code Ocean platform
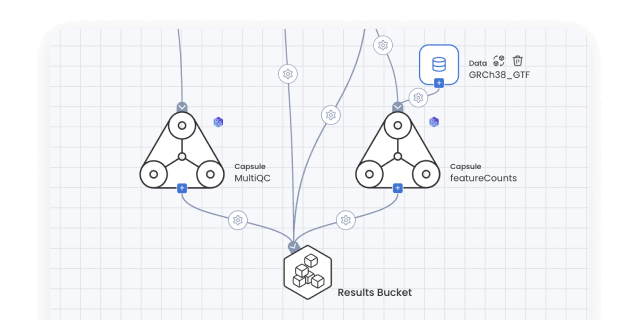
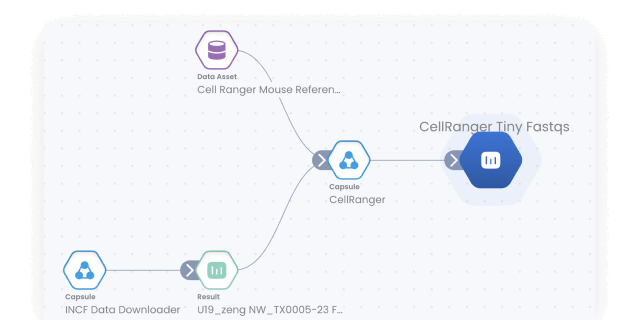
Frequently asked questions
 Compute Capsules
Compute Capsules
How do Compute Capsules work?
Compute Capsules work by creating an immutable record of the code, environment, and data used in computational work, as well as the results produced. They are releasable, versionable, and reproducible. Whatever runs today will always run in the future.
What can you do with a Compute Capsule?
Virtually anything. Simple exploratory analysis, training machine learning models, creating API connections, building visualization apps, and more. However, you can do all these things at the same time as attaching data of any size, provisioning compute, and co-developing with others, all while creating an automatically traceable and reproducible record of work.
What cloud workstations are available for developing code?
VSCode, JupyterLab, RStudio, CLI, MATLAB, Shiny, Streamlit, Ubuntu Desktop (Beta) and IGV (Beta).
How are Compute Capsules different from just using Docker?
Docker is just one piece of what makes up a Capsule. Docker is natively integrated into Code Ocean so users don’t need to be familiar with Docker to take advantage of its containerization technology. One example is the automated Dockerfile generation.
Do Capsules integrate Git? Can you connect Capsules to your Git provider?
Both. All Capsules (and Pipelines) on Code Ocean integrate Git to track changes as development progresses, regardless of whether or not you’ve connected Code Ocean to your Git provider. We have native integrations for Github, Gitlab, Bitbucket and Azure DevOps.
Is there a file size limit for data you can add to a Capsule?
No. You can attach data of any size to any Capsule. Data and Capsules are managed separately, meaning you can attach the same data asset to multiple Capsules at the same time, reducing data duplication, and potentially decreasing the total cost of ownership over time.
Built for Computational Science
-
Data analysis

Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
-
Data management

Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
-
Bioinformatics pipelines

Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
-
ML models
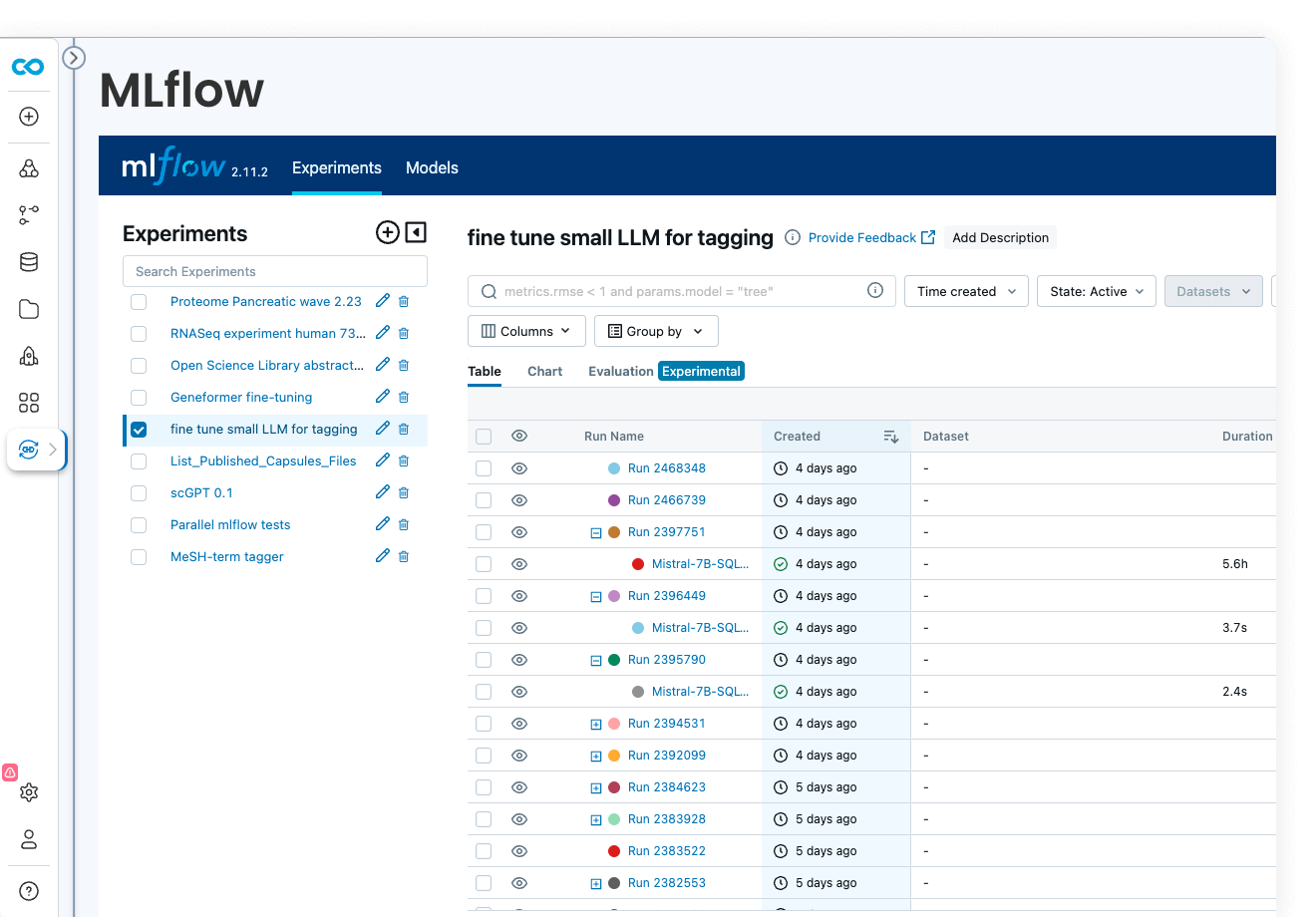

ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
-
Multiomics


Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
-
Imaging
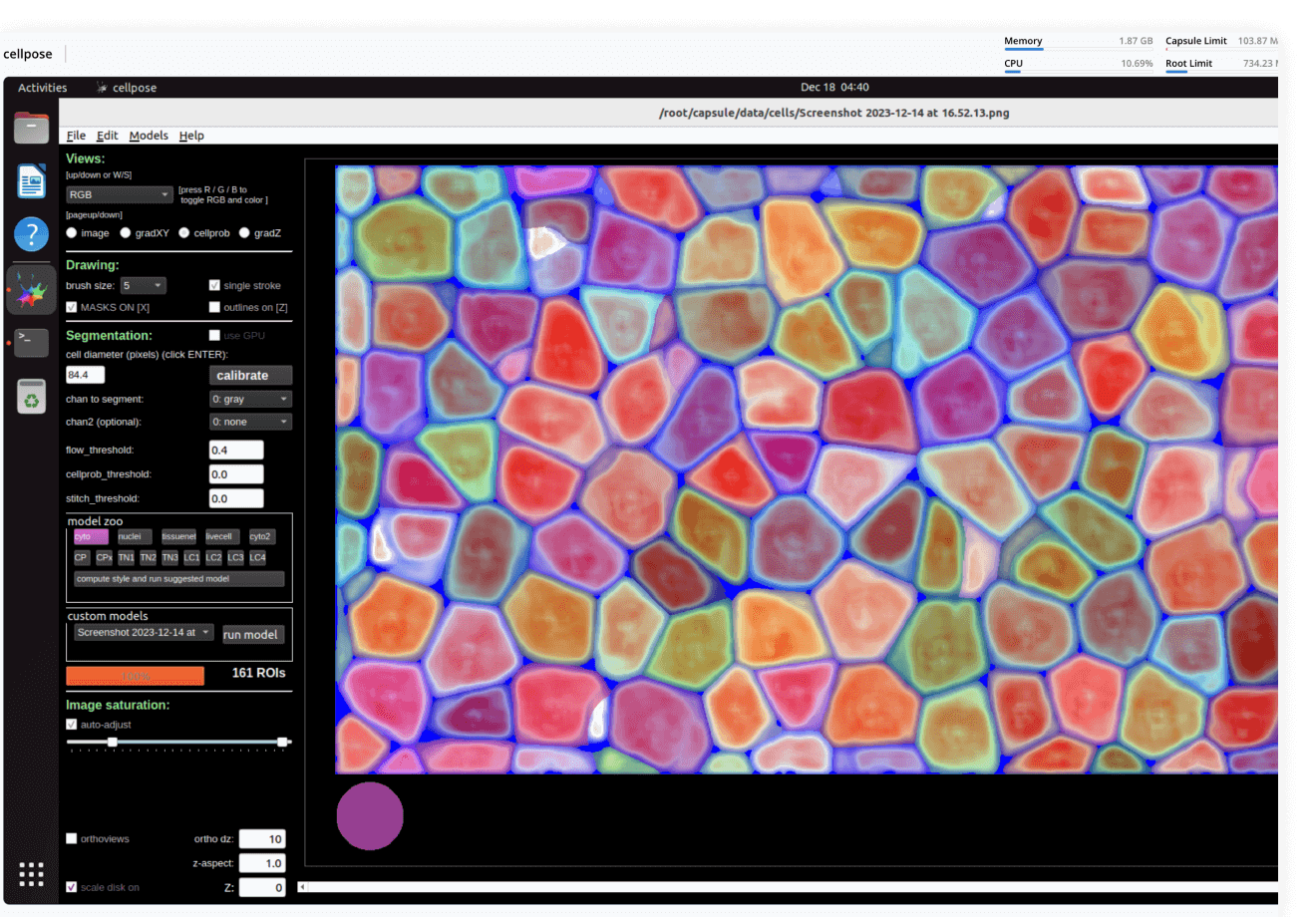

Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
-
Cloud management


Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
-
Data/model provenance

Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
.png?length=720&name=September%20Webinar%20-%20On%20Demand%20(1).png)
