.svg)

Data
A single place to manage all data assets in the cloud and from any other source. Use in computational work while tracking lineage, ensuring reproducibility, and reducing duplication.


Key capabilities
Manage data from multiple sources
Use data from multiple sources in your computational work. Native support for AWS S3, Athena, and Databricks. Choose whether data is brought into Code Ocean for enhanced reproducibility and performance, or remains external for convenience.

Attach Data instantly to any analysis or pipeline
Data are managed separately from Capsules and Pipelines. This means a Data asset can be used in multiple Capsules, Pipelines, and by multiple users simultaneously and without duplication. All recently used internal Data are cached to EFS for fast access.

Track and share data with others
All Data can be shared with other users and/or groups in your AWS deployment with built-in permission and access control.

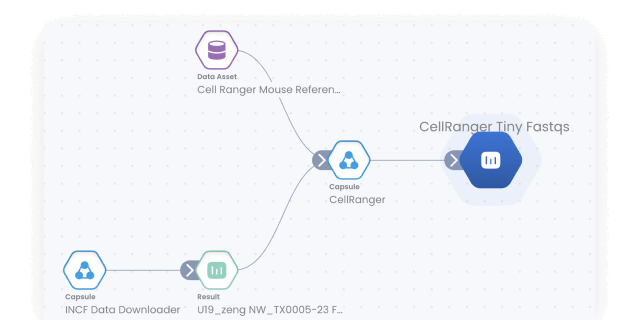
Get instant provenance for all result data
Track Result provenance with the Lineage Graph. Click into any Result Data to see where it came from and how it was generated.

How Data works with the rest of the platform
Frequently asked questions
 Data
Data
Where is my data stored?
Internal Data that you’ve brought into Code Ocean for enhanced reproducibility are stored in an organized S3 bucket inside your AWS account. External data remains external and is accessed by linking to S3 bucket locations.
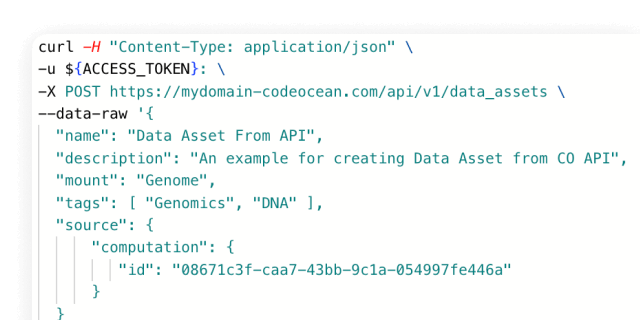
Where can I bring in new data from?
Virtually anywhere. You can bring in data by local upload, and native integrations include AWS S3, AWS Athena, and Databricks. Code Ocean Apps offers several custom Data Connector Capsules, or you can make your own by connecting through API.
Are there any limits to the size of data I can work with?
No. There are no limits to the size of Data that Code Ocean supports, and any data asset can be connected to any Compute Capsule or Pipeline.
Is my data safe?
Yes. Code Ocean supports user Secrets for any credentials that are required to access private data and assumable IAM roles.
Can I share data?
Yes. Data can be easily shared with users and groups. Secrets and Roles ensure data access is a seamless experience for users.
Do you support custom metadata?
Yes. Admins can create custom keys and specify value and input types for users. Custom metadata allows for improved search, management, and organization of data.
Built for Computational Science
-
Data analysis

Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
-
Data management

Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
-
Bioinformatics pipelines

Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
-
ML models
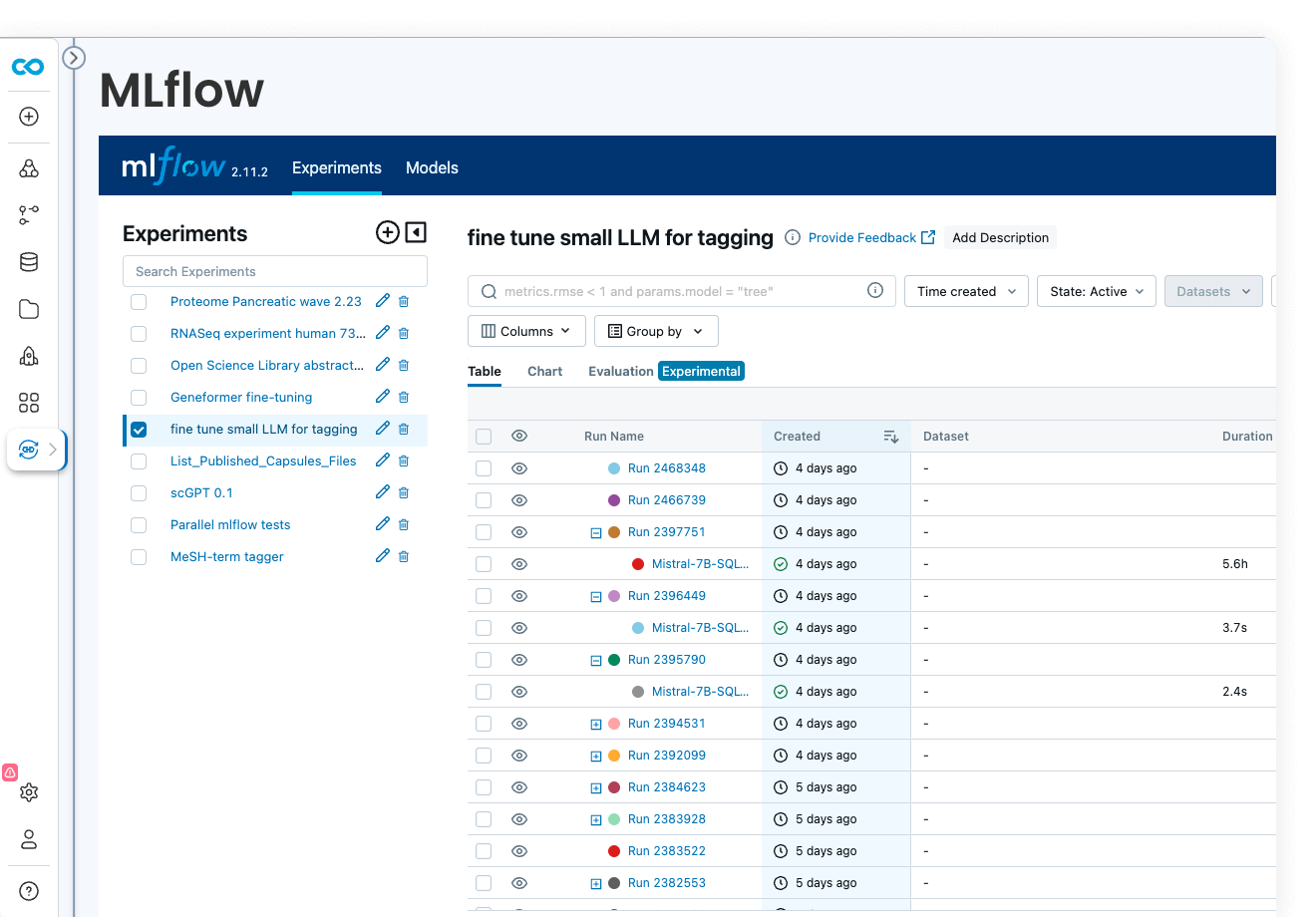

ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
-
Multiomics


Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
-
Imaging
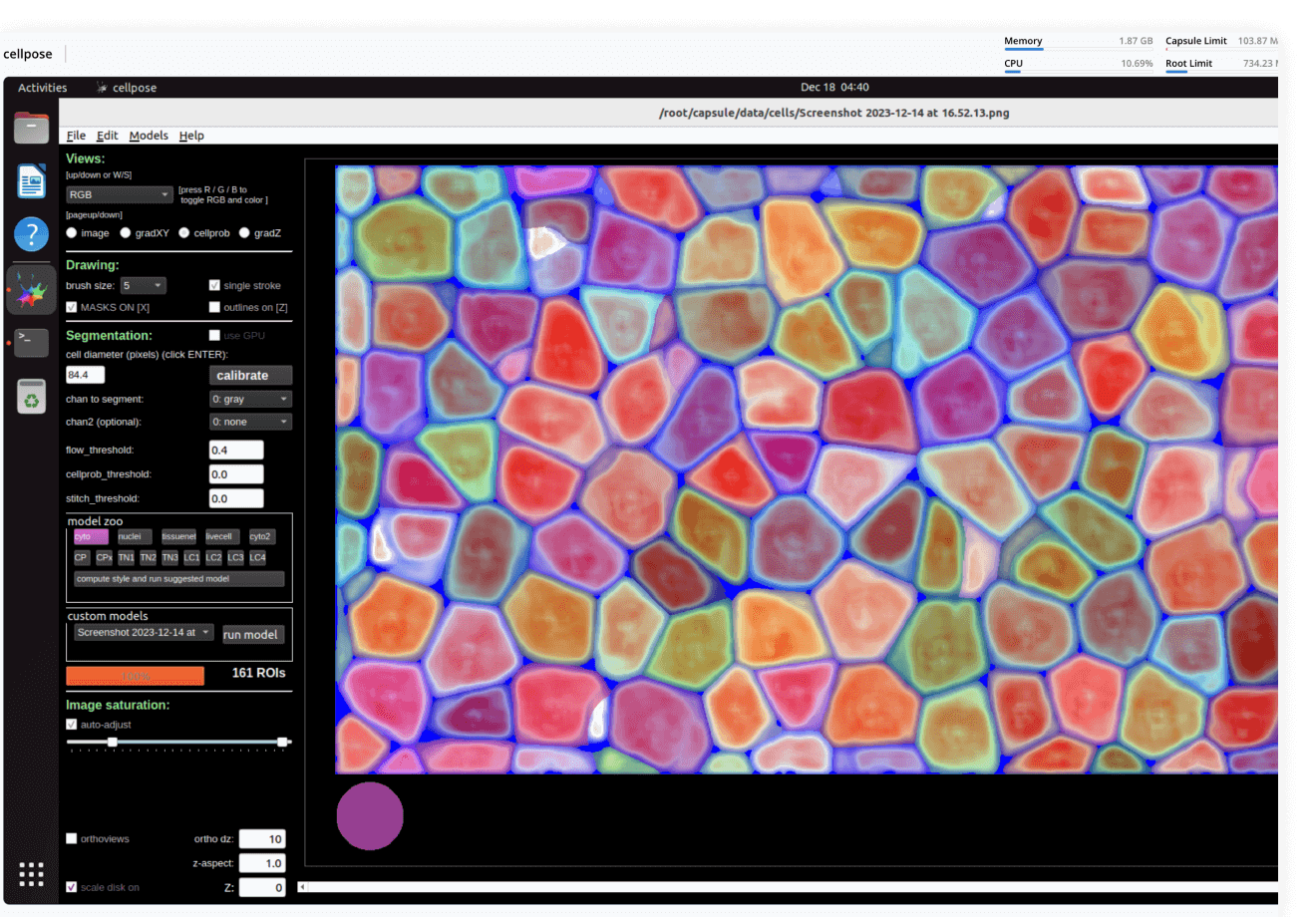

Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
-
Cloud management


Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
-
Data/model provenance

Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
.png?length=720&name=September%20Webinar%20-%20On%20Demand%20(1).png)
