.svg)

 Compute Capsules
Compute Capsules
A shareable, traceable, reproducible containerization of the code, data, and environments used in computational research, version controlled and linked to the results they produce.

 Pipelines
Pipelines
Connect, automate, parallelize, and scale computational work. Build with the visual editor and auto-generate Nextflow code, import from nf-core, or write your own.

 Models
Models
Develop, train, track and register machine learning models in a unified environment with native MLflow integration. Creates a traceable, reproducible record of data/model provenance.

 Data
Data
A single place to manage all data assets in your cloud and from external sources. Use in computational work while tracking lineage, ensuring reproducibility, and reducing duplication.

 Lineage Graph
Lineage Graph
An immutable record of how result data are generated in Code Ocean, showing the source(s), data processing through Capsules and Pipelines, and the output.

 Collections
Collections
Gather and organize Capsules, Pipelines, Apps, and Data by project and scientific area of interest to make them more visible, accessible, and usable by others.

 Apps
Apps
Browse a selection of pre-installed apps ready to use in bioinformatics workflows, and take advantage of functionality to transform computational work into no-code apps for others to use.

 Admin panel
Admin panel
A single pane of glass for all users, resources, and data in the deployment. Manage integrations, cost and compute, and environments in a unified management console.

 API
API
The Code Ocean API enables programmatic access without using the web interface. Tap into core functionality like running computations, creating data, retrieving metadata, and more.


Built for Computational Science
-
Data analysis

Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
-
Data management

Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
-
Bioinformatics pipelines

Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
-
ML models
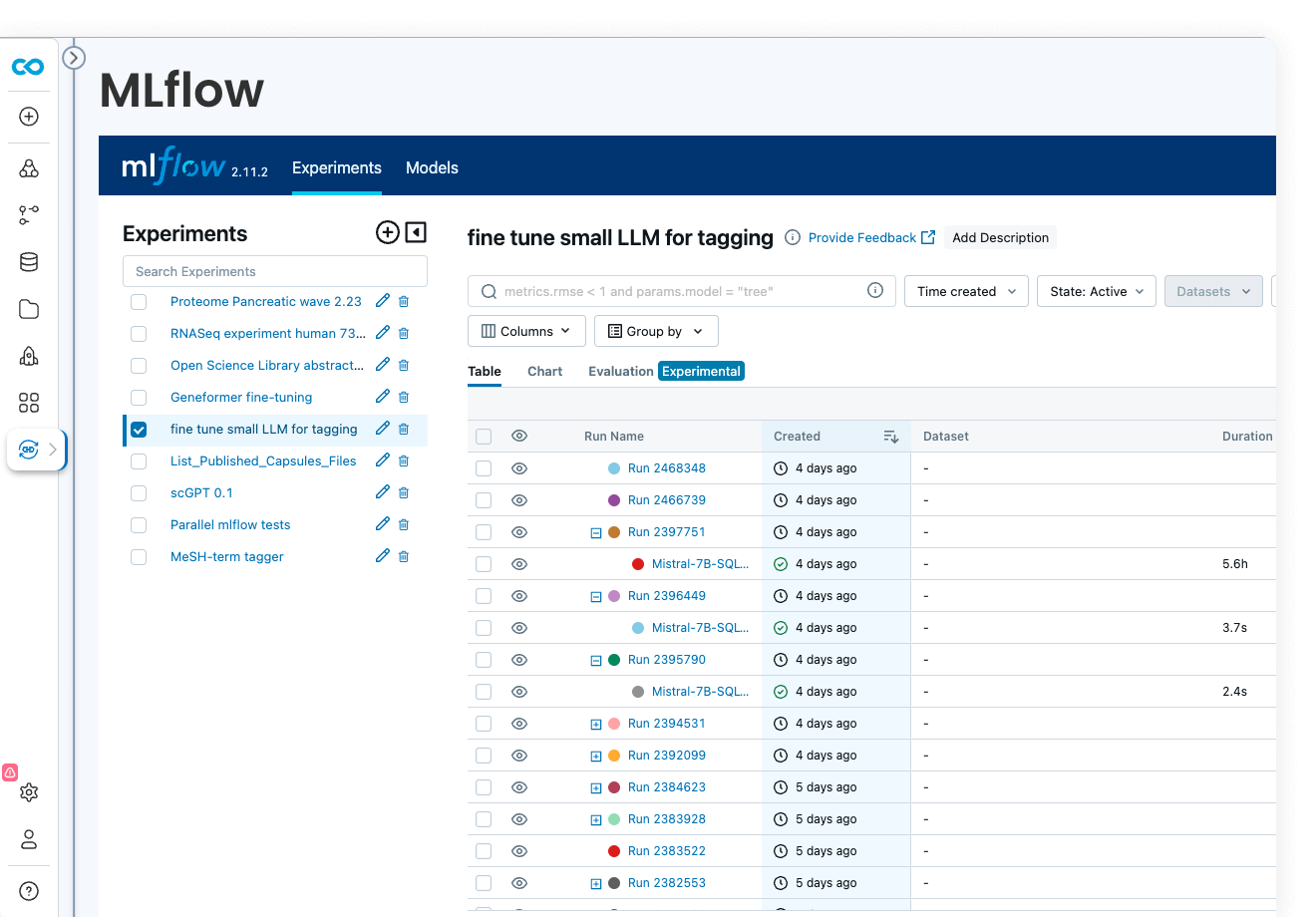

ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
-
Multiomics


Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
-
Imaging
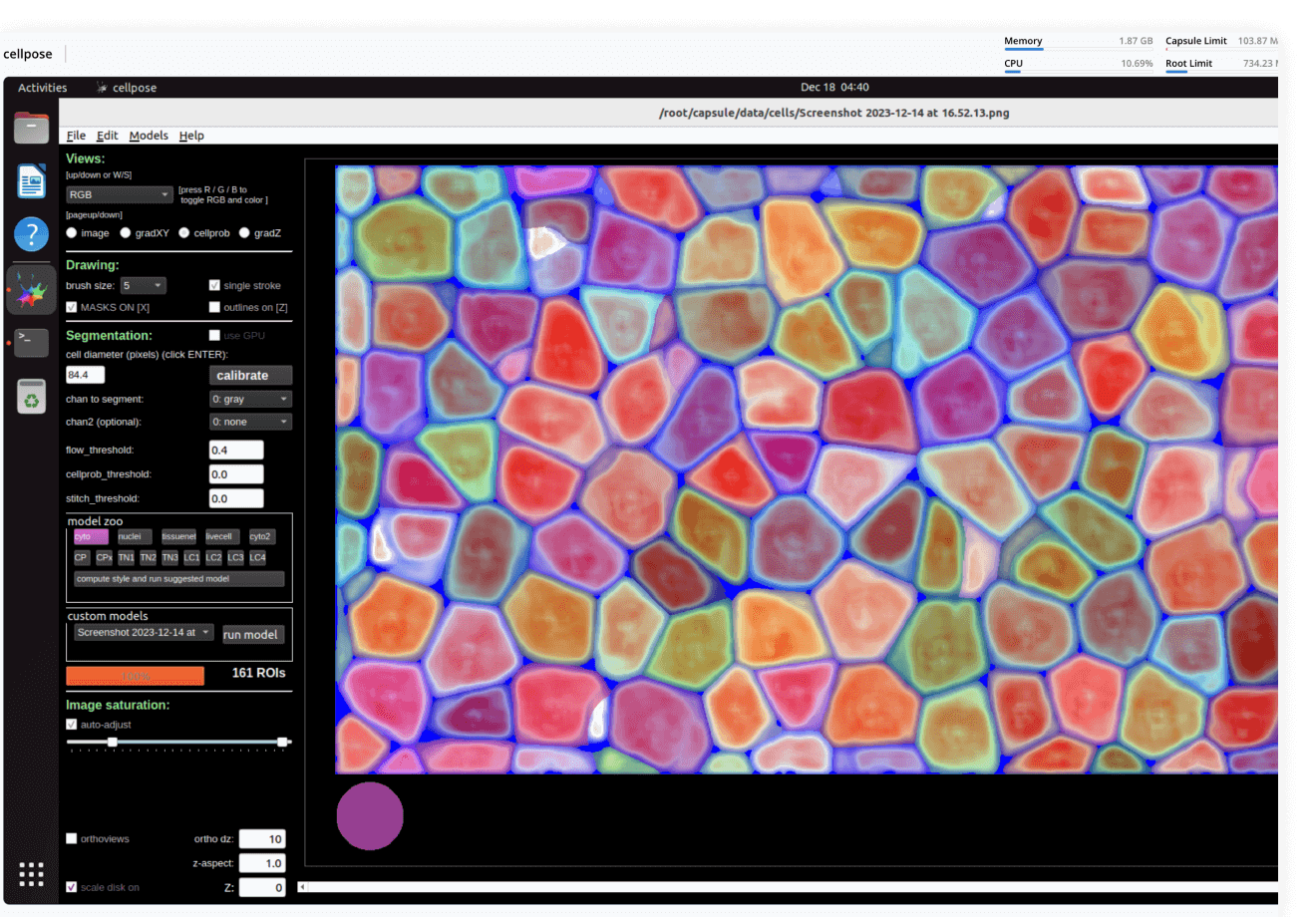

Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
-
Cloud management


Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
-
Data/model provenance

Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.