.svg)

Computational science in the cloud.
Self-service, scalable, reproducible.
Code Ocean is for biotechs starting out, expanding, or working at scale. Get guaranteed reproducible computational science in the cloud from day one, without the DevOps workload.
Trusted by thousands of computational researchers across the life sciences:












Key benefits for biotechs
Easy to start in the cloud, easy to scale in the cloud
Automated environment setup and compute management means you can use the full power of AWS without having to log in to AWS. Build a Capsule in minutes, launch a cloud workstation to develop your analysis, then run it in the cloud in just a few clicks.

Share and collaborate in a secure cloud environment
Users can share everything from basic analyses to complex pipelines with other individuals or whole groups, making it easy to work together. Code Ocean integrates SAML and OIDC as well as SCIM to allow administrators to work with your existing Identity Provider (IdP).

Assemble, import, & deploy bioinformatics pipelines
Use a visual editor that generates Nextflow code in real time as you build. Import existing pipelines from nf-core, clone from a Git repository, or customize by unlocking the editor to write your own code. Runs on a pre-configured AWS Batch instance, enabling parallelized computing.

Pharma-readiness with automated reproducibility and traceability
Code Ocean automatically creates an immutable record of all computational analyses ensuring complete traceability and data provenance from initial source data, through upstream processing and downstream analysis, all the way to final results.

Easy to build and deploy no-code Apps for others
Compute Capsules and Pipelines can be adapted into paramaterized Apps for distribution throughout the rest of the organization, including to non-coders. Also includes RShiny and Streamlit integrations.

Who uses Code Ocean?
What our customers say:
“Code Ocean sped up our internal image pre-processing computational workflow by at least 10x, improving collaboration and productivity between our global teams ... removing the need for painful cloud computing infrastructure set up.”

What our customers say:
“Code Ocean's self-service capabilities make it easy for our scientists to do their work reproducibly. New users to the platform can get far with just a little support, giving our engineers time to focus on domain-specific challenges.”

What our customers say:
“Code Ocean totally solves tracking and reproducing analysis for researchers and increases trust in the results.”


How Ochre Bio automated a manual image processing workflow with Nextflow
Key product features

Built for Computational Science
-
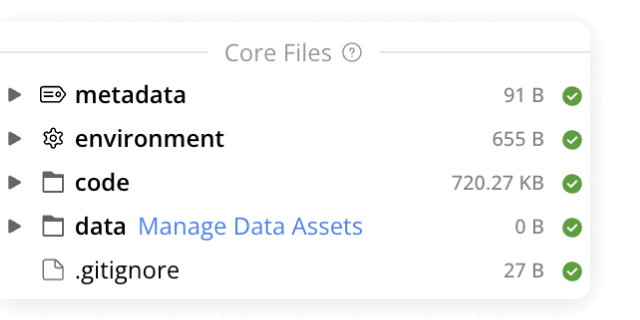
Data analysis

Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
-
Data management

Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
-
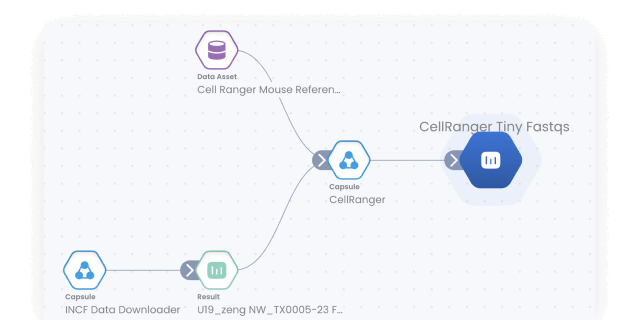
Bioinformatics pipelines

Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
-
ML models
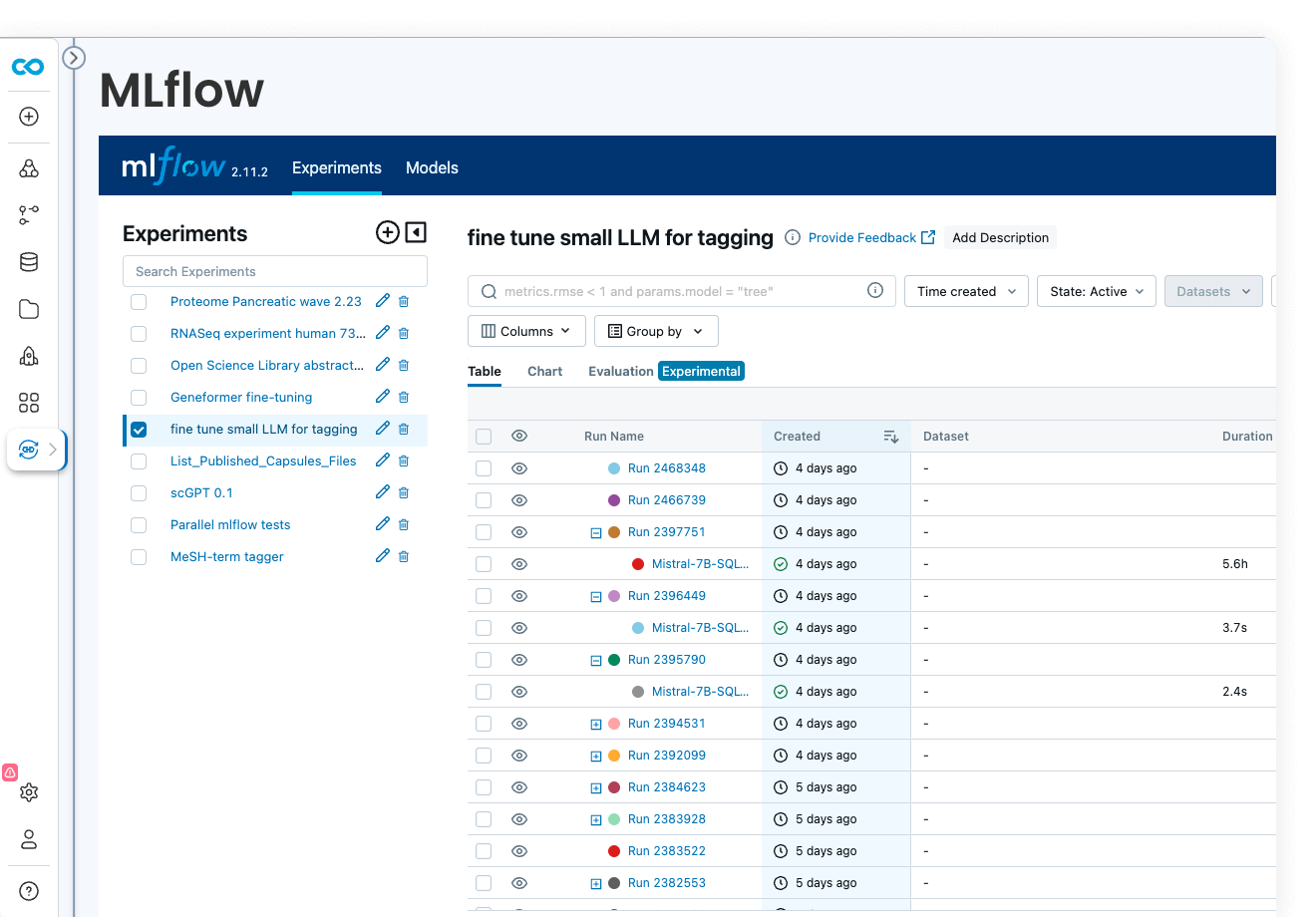

ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
-
Multiomics


Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
-
Imaging
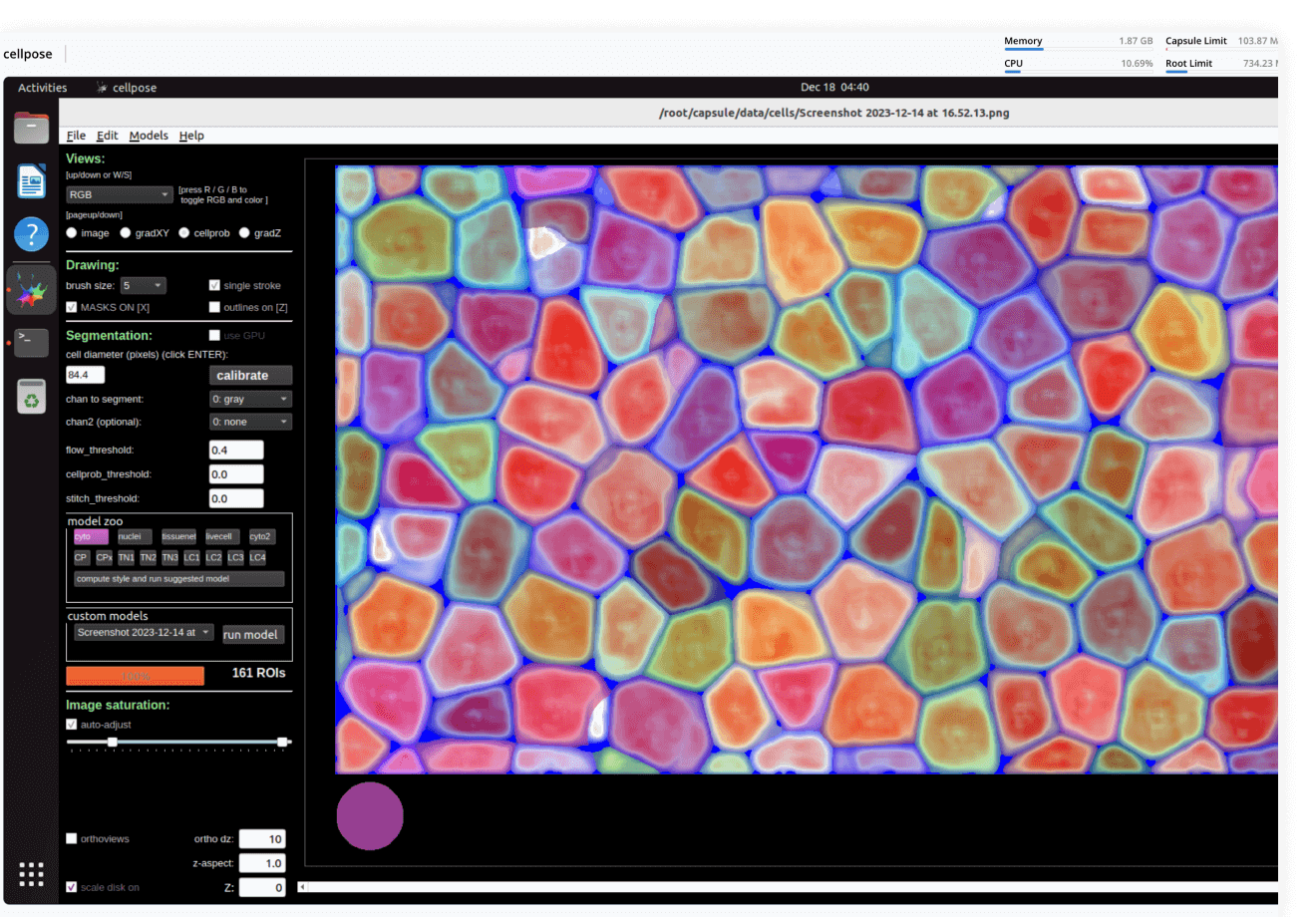

Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
-
Cloud management


Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
-
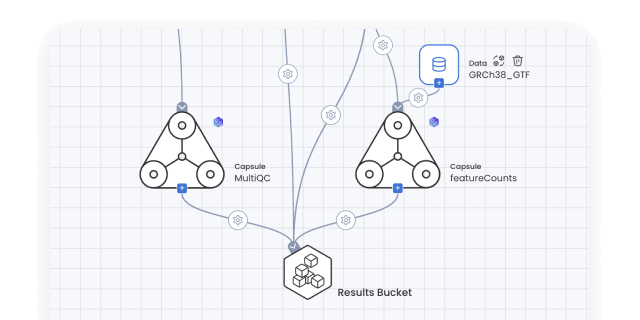
Data/model provenance

Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
.png?length=720&name=September%20Webinar%20-%20On%20Demand%20(1).png)
